自從1998年LeNet-5的問世,以及2012年異軍突起在ImageNet比賽上展露頭角的AlexNet之後,VGG架構的出現讓CNN的設計進入一個新的紀元,幾乎所有的架構都設計得越深越複雜,希望可以獲得更好的模型表現,不過這樣也會帶來一些問題,我們今天會從這個角度出發,順便看看有沒有甚麼解決方法。

H(x))可以輸出我們最想要看到這答案,這個尋找最佳函數的過程就是一種最佳化。作者的意思是不同的架構很難用同一種最佳化方法處理,所以當我們都使用梯度下降的時候,很難讓所有的架構都得到最佳表現,作者還舉了一個極端情況的例子:把前面那個56層的模型後面36層都只學習恆等式取代(也就是輸入等於輸出),理論上這樣的結構跟20層的是一模一樣的,都是只有前面20層在學習,但是實驗結果,性能上卻是仍不及20層的模型,這是因為要讓模型學習恆等式(H(x)=x)是很困難的,也不好收斂。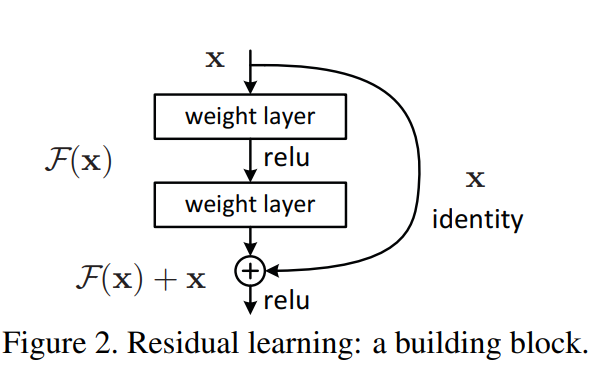
F(x)=H(x)-x等於0,也就是殘值(Redidual)時,就會是我們希望的恆等式(H(x)輸出結果等於短路(Shortcut)值x的結果,一來,將較於上面的表示法,這樣的形式從數學的角度來講是比較好進行最佳化的,二來,這種將資訊直接往後傳遞的方式,也可以避免資訊傳播路徑太長而被稀釋掉的問題。更詳細的討論內容可以參考:https://reurl.cc/QZXk10 與 https://reurl.cc/l7Drkv
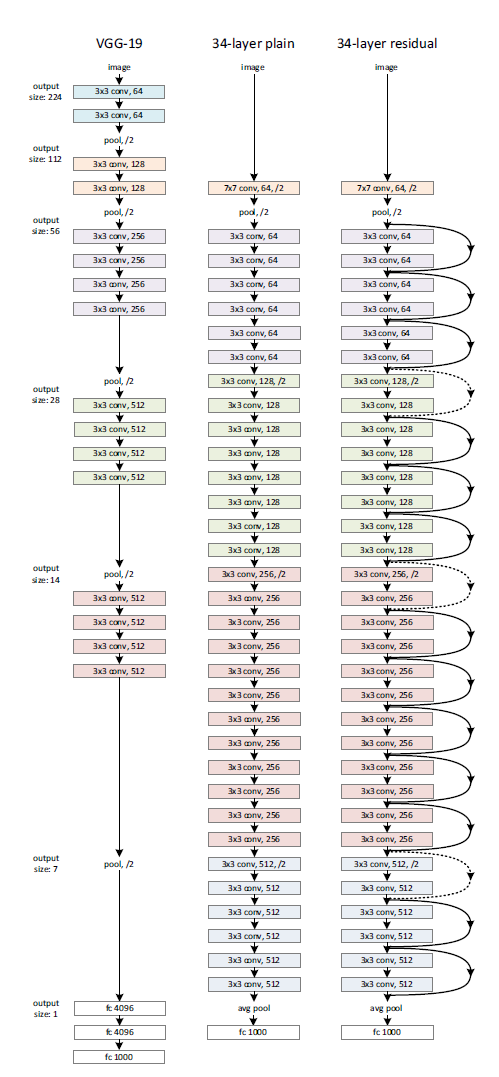
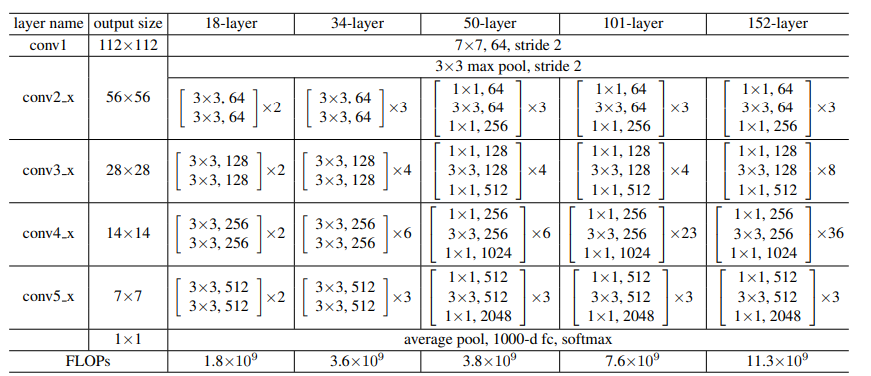


 iThome鐵人賽
iThome鐵人賽